Recycling UI strings is bad
I work in localisation among other areas of translation and I know it’s very tempting to re-use texts that one might think are “the same”. (What a money-saver it is, too!)
If only it was that simple.
One problem is caused by the grammatical gender. Here’s a simple example from a text I was working on today (it won’t give anything away): the word “Saved” — that was the whole UI string. In English and many other languages it can easily be translated and re-used without a problem. But in for example Spanish (I pick a language I know) you need to know what has been saved because the adjective/past participle is inflected depending on whether the subject is masculine or feminine (salvado or salvada respectively). You can’t use the same 7-character string in all contexts; I suppose most of the time it would just be annoying, in worst cases it might even be confusing.
Just now I borrowed an eBook from the library and looked at the file properties in Adobe Reader 7.0. Here’s what the window looks like:
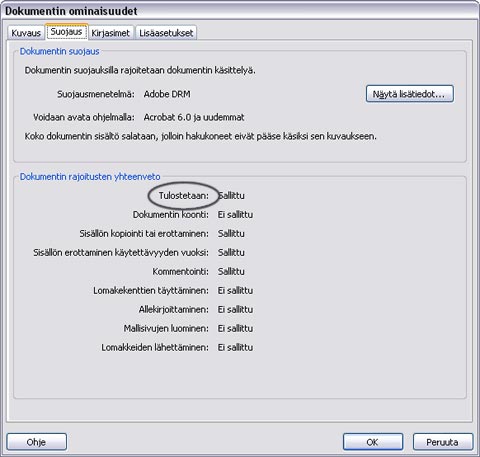
I’ve circled the word Tulostetaan (Finnish). In an English program I’m sure it would say “Printing”, that is “Printing is allowed/not allowed”. The word can also be used when you print a page and the program lets you know that it’s busy doing something by displaying “Printing” or perhaps “Printing…” with animated fullstops. The words do look the same but they don’t mean the same. The problem in Finnish (and other languages) is that, if translated correctly, the words do not look the same. “Tulostetaan” can be used in letting us know that the program is busy but not in this context. Here the word ought to be “Tulostaminen”.
Usually recycling is encourageable — not in localisation I’m afraid.
Addition, Thu 5th October
I don’t know what has “gone wrong” with the above localisation, and I don’t know if the two (or more) strings are perceived as the same (i.e. use the same resource) or if they just have been copied to save money/time/trouble. They shouldn’t be perceived as the same because they clearly aren’t. Some problems could perhaps be solved if at least words that are of different parts-of-speech would be separated from one another (noun printing vs. gerund printing). Perhaps they are. Do remember that I don’t know a thing about application development or the inner workings of Windows applications (among others) so I have no idea what’s going on under the hood.
I suppose WordPress functions similarly (“the wrong way”) because it uses GNU Gettext framework where texts are translated on message level. At closer look it does look like the context is taken into account, though, so problems like in this example on multiple meanings of “post” are avoided. Way to go!